- Published on
AI-powered audio briefly transcriptions
- Authors

- Name
- Alejandro Perdomo
- @alejandropr05
Introduction
In educational, work or personal environments, we often face the difficulty of managing long audios, such as classes or meetings, whose content exceeds our available time to listen to them in their entirety. This results in a loss of valuable information and can affect the comprehensive understanding of the subject matter. “Briefly” addresses this problem by offering an effective solution that allows users to receive audio files, accurately transcribe them, and then generate automatic summaries.
The app uses OpenAI's Whisper to perform high-quality transcriptions, ensuring accurate representation of spoken content in audio files. It then uses the Transformer T5 model to generate concise but informative summaries, capturing key points and highlighting essential information.
Used models
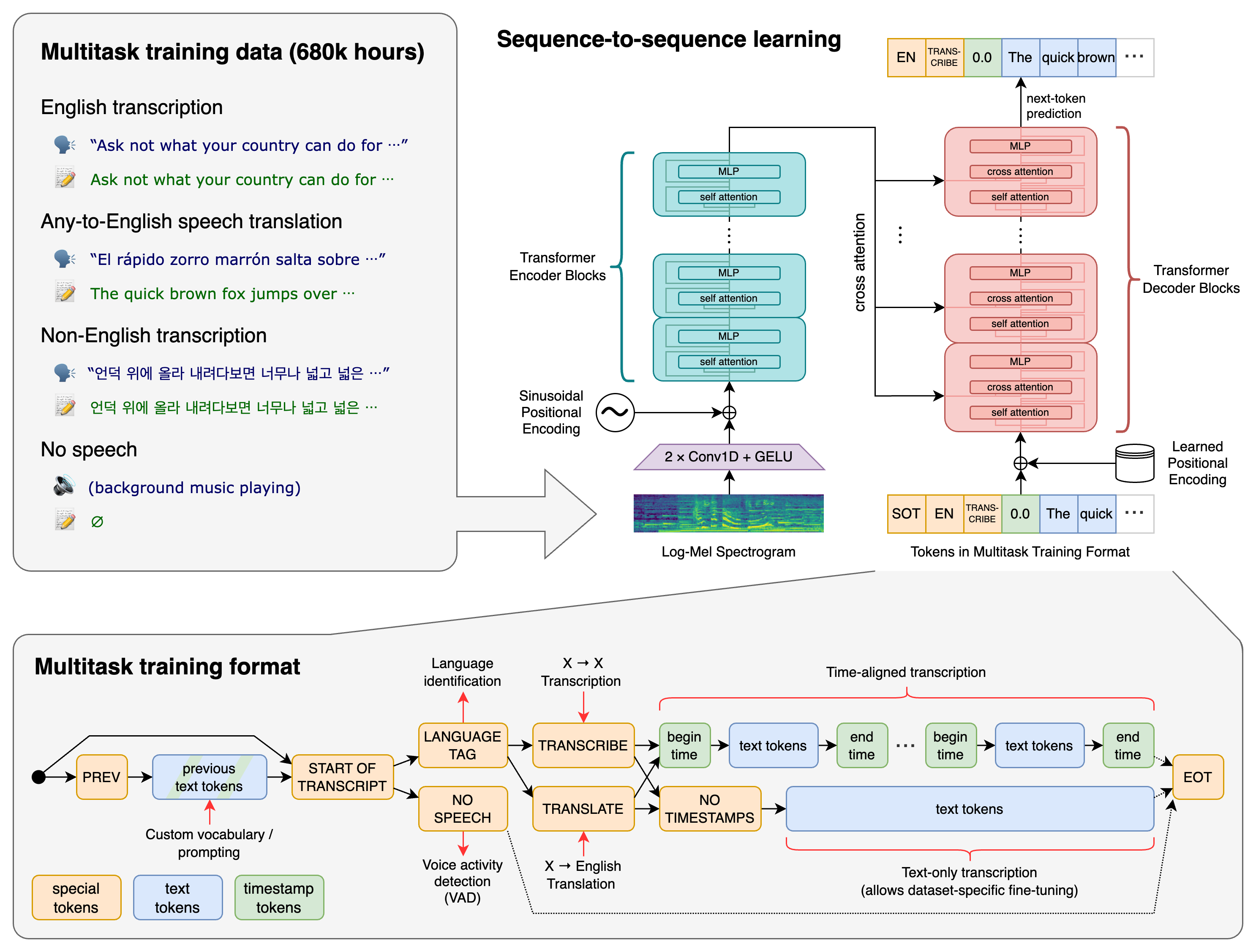
Whisper
Whisper is a model developed by OpenAI designed specifically to perform audio transcription tasks. Its architecture consists of an encoder-decoder transformer that takes audio log-Mel spectrograms as input.
Available Models
There are five available models offered by OpenAI, of which four are English-only. Each model differs from the other in terms of speed and accuracy.
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en | tiny | ~1 GB | ~32x |
| base | 74 M | base.en | base | ~1 GB | ~16x |
| small | 244 M | small.en | small | ~2 GB | ~6x |
| medium | 769 M | medium.en | medium | ~5 GB | ~2x |
| large | 1550 M | N/A | large | ~10 GB | 1x |
Transformer T5
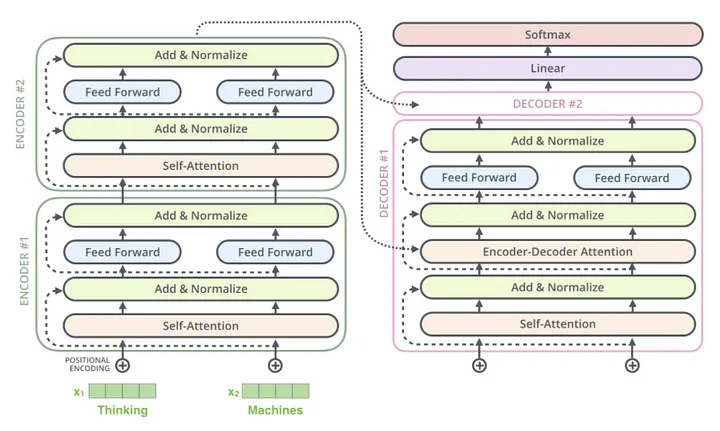
Transformer T5, presented in Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer, is a unified approach for all Natural Language Processing (NLP) tasks, using a text-to-text format, where the input and output are text strings. “T5” refers to the core functionality of the model, which is called “Text-to-Text Transfer Transformer”.
T5 is an encoder-decoder model that converts all NLP problems into this format. It is trained with "teacher forcing", requiring an input sequence and a target sequence for training. The model can be trained or tuned in a supervised or unsupervised manner.
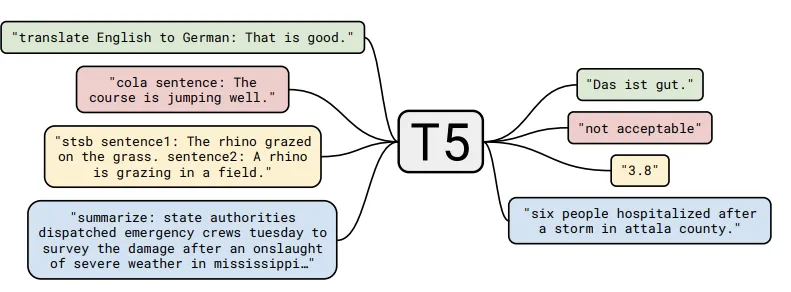
Available Tasks
Below is a diagram of the text-to-text framework. Each task considered (including translation, question answering, and classification) is cast as feeding the model text as input and train it to generate a target text. This allows the same model, loss function, hyperparameters, etc. to be used in this diverse set of tasks.
Demo
To demonstrate how these two models work together, a demo web application was developed in which the user can enter audio files and a summarized transcript will be returned.
To develop this application it was divided into two main functions, backend and frontend. For the backend, an endpoint "/summarize" was created with use of FastAPI. For the frontend, Next.js and Tailwind CSS were used
You can found the repository here.